
Generative AI and large language models (LLMs) have transformed the way businesses harness data to derive insights and make strategic business decisions. These models possess incredible power, and services like Amazon Bedrock and Amazon SageMaker Jumpstart have further amplified these opportunities and challenges, making it easier for businesses to integrate GenAI into their operations and innovate more efficiently. During this rapid phase of digital transformation,
Retrieval-Augmented Generation (RAG) is becoming an essential tool for technical teams to build solutions that caters to specific business requirements of the users. RAG improves the performance of large language models (LLMs) by linking them to external sources of information, allowing the models to provide more accurate and relevant answers based on up-to-date data. This approach enhances the quality of AI-generated results, enabling businesses make decisions based on true information. By retrieving the right information when needed, RAG ensures that the AI is better aligned with the specific requirements of the business.
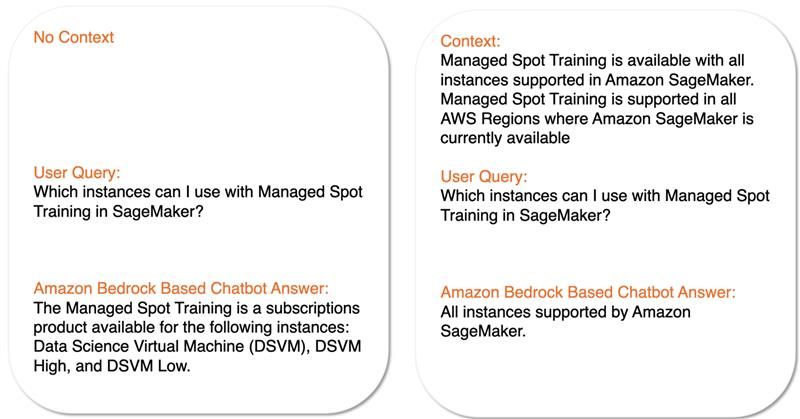
One of the greatest advantages of RAG is that it helps minimize hallucinations in large language models (LLMs), which happens when the AI produces incorrect or misleading information. By connecting the models to reliable external data sources, RAG provides the LLM with a trustworthy context, reducing the risk of incorrect responses. This further ensures that the insights and recommendations generated by AI are not only more accurate but also more relevant, helping businesses make better, more informed decisions.
When to Use Retrieval-Augmented Generation
The approach selection is influenced by three key business factors: the need for domain-specific solutions, access to current information, and the extent of required domain adaptation. While there are several technical considerations, they generally fall under cost, effort, and technical expertise.
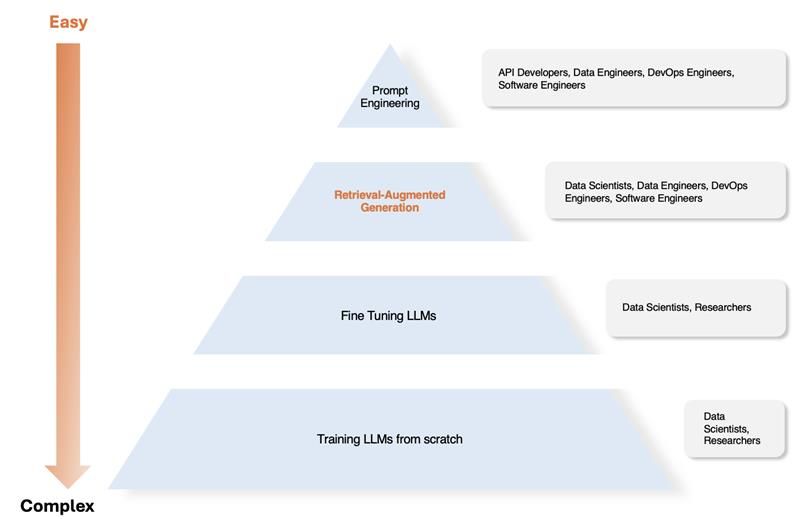
Given below is a guideline that helps navigate this exact question effectively.
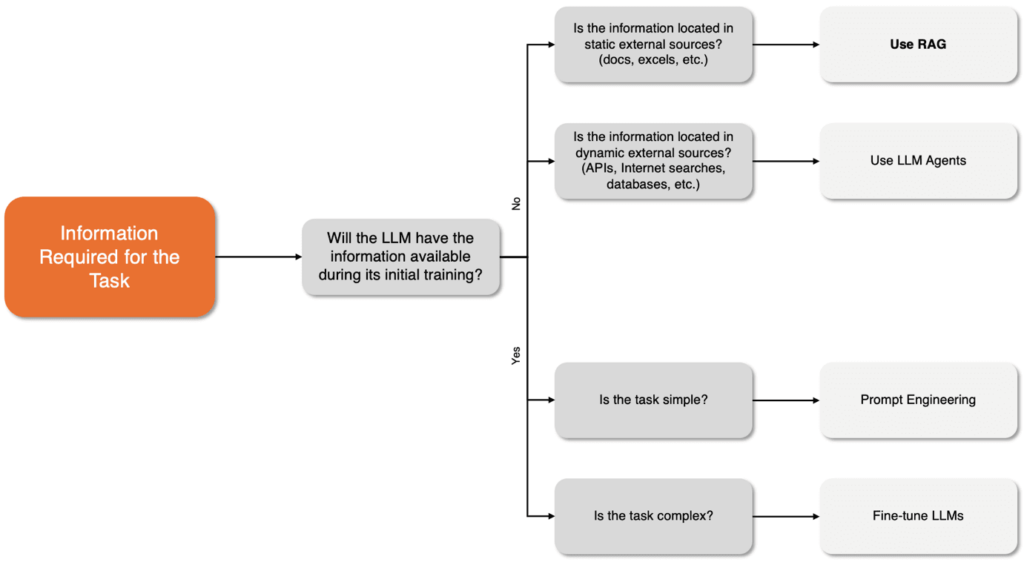
Interestingly, training an LLM model from scratch isn’t included in the guidelines at all. Unless you’re conducting research, this should always be a last resort, as it’s highly resource-intensive in terms of cost and effort. However, you won’t have clarity on its performance until the entire training process is completed.
Scenario 1: Using LLMs to Generate Medical Diagnoses from Medical Records
Will the LLM have the necessary information during its initial training? Most large language models are trained on a wide range of publicly available data. Medical datasets, for example, are commonly accessible on platforms like Kaggle and Hugging Face Datasets. Therefore, in this case, the LLM would likely have the information needed during its initial training. Is the task simple? No. Is the task complex? Yes, which is why we fine-tune the LLM.
Scenario 2: Developing a Chatbot to Access Company Policy Documents
Will the LLM have access to the necessary information during its initial training? No, because this is company-specific data that is likely not public. Is the information stored in static external sources (e.g., documents, spreadsheets, etc.)? Yes, most of these documents are relatively static and do not change often. Therefore, we will use RAG to retrieve and incorporate this information as needed.
Demystifying RAG
RAG combines two cutting-edge technologies: information retrieval (IR) and natural language generation (NLG). To appreciate the innovation RAG offers, it’s essential to understand the complex interaction between these two elements.
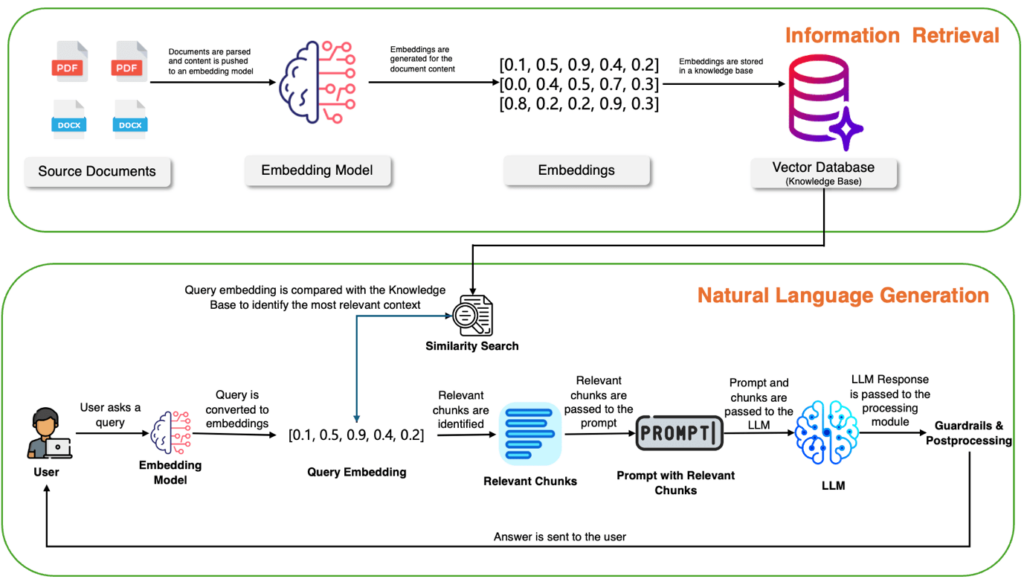
Information Retrieval – The Search for Relevance
The IR process begins by converting source documents—such as PDFs, Word files, or databases—into numerical representations called embeddings using advanced AI models. These embeddings capture the essence and meaning of the documents, which are then stored in a specialized vector database, often known as a knowledge base. When a user submits a query, it is similarly transformed into an embedding. This query embedding is then compared to the knowledge base through a similarity search, allowing the system to identify the most relevant information that aligns with the intent behind the query. This ensures that the data retrieved is highly relevant, filtering through both structured and unstructured sources. For business applications, the IR system must be finely tuned to handle industry-specific jargon and nuances, ensuring precision and relevance in delivering the right data.
Natural Language Generation – The Art of Articulation
Once the relevant information is retrieved, the NLG component brings the data to life. The retrieved chunks are combined with the user’s query to create a comprehensive prompt, which is then passed on to a powerful large language model (LLM). The LLM synthesizes this information, generating a coherent, contextually rich response that mimics human-like articulation. Before reaching the user, this response undergoes post-processing, where it is refined and filtered to ensure clarity, relevance, and quality. The result is not just a straightforward answer but an insightful and polished response, providing both depth and accuracy. This seamless interplay between retrieval and generation enhances the user experience by offering responses that are precise, context-aware, and easy to understand.
Challenges of RAG
1. Managing diverse data sources: Handling various structured and unstructured data types is complex, requiring regular updates and managing different formats.
2. Generating vector embeddings for large datasets: Creating vector embeddings for extensive data is resource-intensive, demanding substantial processing power and memory.
3. Updating the vector store incrementally: Keeping the vector store updated with new data while maintaining data consistency and avoiding downtime is a significant challenge.
4. Development effort: Implementing RAG involves substantial coding to effectively integrate models, vector databases, and retrieval mechanisms.
5. Scaling retrieval systems: As data volumes grow, it becomes difficult to scale retrieval mechanisms efficiently without advanced indexing and infrastructure solutions.
6. Orchestration of components: Effectively managing the integration of processes like model inference, retrieval, and ranking into a seamless pipeline requires sophisticated orchestration.
7. Addressing ethical concerns (bias and fairness): Ensuring that the retrieval and generation processes remain unbiased, and fair is crucial to avoid ethical issues.
8. Monitoring and performance tracking: It’s essential to maintain transparency in system performance and address bottlenecks or failures quickly to ensure smooth LLM functionality.
Conclusion
In conclusion, while LLMs are trained on vast datasets, they often struggle to stay current and incorporate proprietary or domain-specific data, leading to “hallucinations” — where models confidently provide incorrect or misleading responses.
Retrieval-augmented generation (RAG) mitigates this issue by enhancing LLMs with real-time, context-aware data retrieval, but it comes with its own set of challenges. These include managing diverse data sources, updating the vector store efficiently, and ensuring retrieval accuracy at scale.

In the upcoming blog, we will dive deep into the technical aspects of RAG, exploring how AWS technologies and services can effectively support Retrieval-Augmented Generation needs while ensuring seamless integration and scalability for an organization.
Still curious how RAG can streamline your operations? LUMIQ has the answers.


