
In the previous blog, we explored the impact of Retrieval-Augmented Generation (RAG) from both a business and technical perspective, diving deep into how it can transform decision-making processes and be implemented using AWS Cloud infrastructure. However, a critical challenge that remains when using large language models (LLMs) is the issue of hallucinations—where models generate responses that are plausible but factually incorrect with absolute confidence.
To tackle this, LLMs can be augmented with traditional machine learning techniques, providing a more grounded approach and significantly reducing the occurrence of these misleading responses by blending the power of LLMs with the precision of traditional machine learning.
Instead of delving into theoretical explanations, this blog will take a more practical route, highlighting two real-world examples where we successfully applied this hybrid approach. In each case, we utilized traditional machine learning models alongside LLMs to ensure that the outputs were validated against real data and domain-specific knowledge.
Use Case 1: Medical Summarization for a leading Life Insurance company
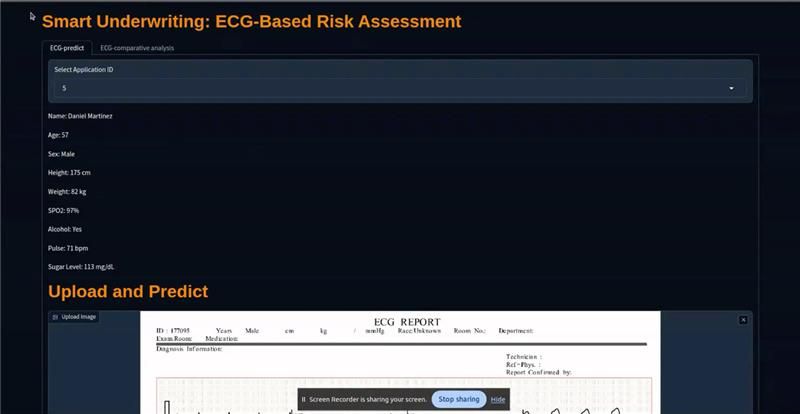
A life insurance company was seeking to streamline and digitize the classification and summarization of their medical documents, particularly Electrocardiograms (ECGs) and Treadmill Tests (TMTs). These medical records are crucial as they provide deep insights into an individual’s heart health, helping insurers assess risk more accurately during the underwriting process.
However, reviewing and interpreting these documents manually has always been a labor-intensive task, requiring skilled medical professionals to sift through vast amounts of data. Not only is this process time-consuming, but it also introduces the possibility of human error, which can lead to misinterpretations, delays in policy issuance, and even flawed risk assessments.
To address these challenges, we implemented a solution utilizing the Vision Transformer (ViT) model to automate the classification of ECGs and TMTs. The ViT models were trained to categorize these medical tests into various classes such as normal, abnormal, or requiring further investigation. Once classified, the system goes a step further by leveraging LLMs to validate and justify the initial classification using a chain-of-thought mechanism. The LLMs analyze the classified data and provide detailed explanations, offering insights into why a specific classification was made, thereby ensuring that the results are accurate and explainable to human underwriters. This approach resulted in a 99% classification accuracy, a significant improvement over using standalone LLMs, which achieved just over 70% accuracy on their own.
By combining ViT’s precision with LLM’s ability to validate and articulate the results, the life insurance company was able to drastically improve the efficiency and reliability of their medical document review process, reducing manual intervention while ensuring higher accuracy and faster decision-making.
Technical Flow
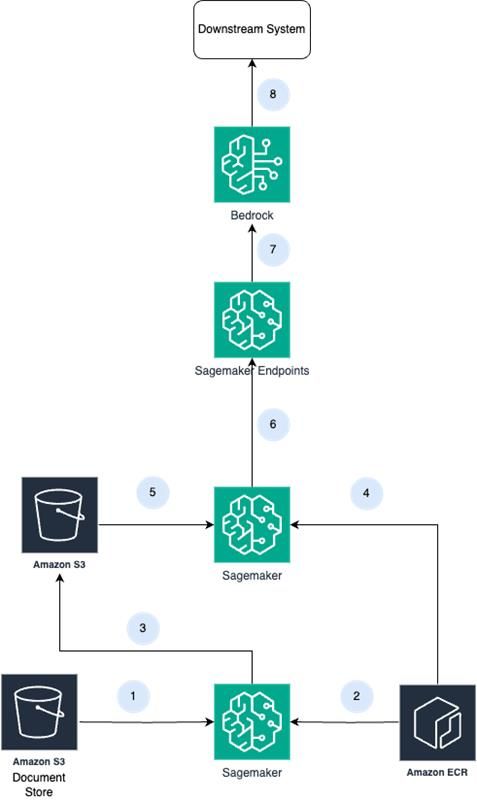
1. Annotated documents are placed in S3. These documents are the training data for the medical summarization service.
2. The training code (which preprocesses the documents, and runs 18 epochs on the ViT architecture) is stored in a container which has been published in Amazon ECR. This is pulled into Sagemaker using its DLC (deep learning containers) integration.
3. Training is performed until the training loss is acceptable, with the objective to just classify each ECG and TMT into normal and abnormal. The trained model artifacts are then stored in an S3 buckets, which acts as the model zoo.
4. Similar to step 2, the inference code is stored in a container within ECR, which is pulled by SageMaker.
5. The model artifacts are pulled from the model zoo (S3).
6. Sagemaker Endpoints are used to accept requests and publish inferences to Bedrock.
7. Bedrock consumes ViT model output as well as the image to generate justification, addition of more details to the classification, explanations, and comparisons. Claude 3 Sonnet performed the best.
8. Output is sent to downstream systems.
Use Case 2: Enhancing Gen AI-based Chatbot for an Assets Management Company
An Asset Management Company (AMC) aims to enhance the experience of its distributors by introducing a conversational AI chatbot that provides quick and accurate responses to queries regarding mutual fund schemes that a customer might have. The chatbot will parse and retrieve information from key documents, such as Scheme Information Documents (SIDs), Key Information Memorandums (KIMs), brochures, and other relevant materials. This solution will allow distributors to access critical scheme-related details like fund objectives, risk factors, expense ratios, and historical performance at a drop of the hat, supporting training, improving efficiency and overall sales.
The documents containing scheme-related information, such as Scheme Information Documents (SIDs) and Key Information Memorandums (KIMs), were highly voluminous and comprehensive. Traditional Retrieval-Augmented Generation (RAG) approaches, which combine document search with generative models, faced challenges in retrieving the most relevant information efficiently. To address this issue, a more sophisticated approach was adopted by leveraging Latent Dirichlet Allocation (LDA), a form of unsupervised machine learning, to extract key themes or topics from the content of these documents.
LDA topic modeling was applied to the document content, where it helped identify underlying patterns by clustering sentences and paragraphs into distinct topics. This process segmented the documents into thematically relevant sections, making it easier to locate specific information. As a result, the chatbot could index and tag various sections more effectively, improving the overall efficiency of retrieving relevant content when needed.
In addition to organizing document content, topic modeling was applied to user queries before they were processed by the large language model (LLM). By analyzing the user’s query through LDA, the chatbot could categorize it into broader themes such as “fund performance,” “risk factors,” “investment objectives,” or “tax implications.” This pre-processing step helped refine the chatbot’s understanding of the query, ensuring that it retrieved the most appropriate and contextually relevant information, especially for complex or ambiguous queries.
Overall, integrating LDA-based topic modeling into both document parsing and query processing significantly enhanced the chatbot’s performance. By accurately identifying thematic relevance and improving query comprehension, the solution not only boosted the accuracy of responses but also streamlined the retrieval of key information. This approach paved the way for a more efficient chatbot that could handle the complexity of the AMC’s comprehensive scheme documents.
Technical Flow
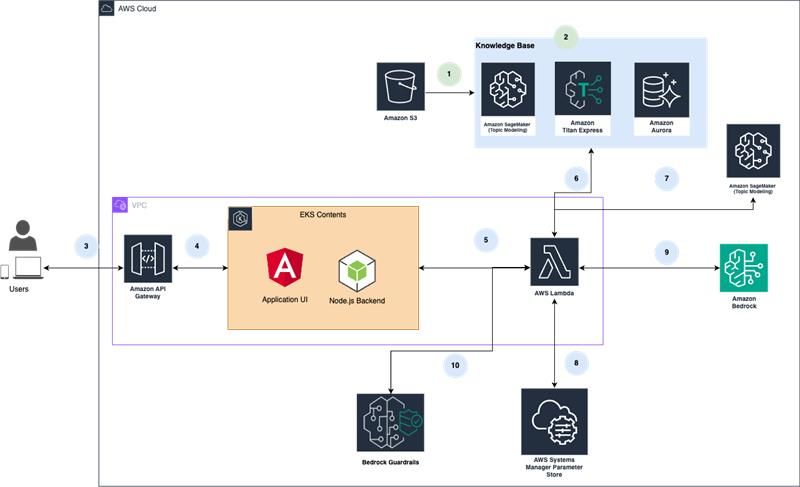
1. Document artifacts (PDFs, DOCs, Excels, etc.) are stored in S3 and serve as reference material for the chatbot.
2. The documents are parsed into paragraphs, passed through SageMaker for topic prediction, and embeddings are generated using Amazon’s Titan Express Model. These embeddings are stored in Amazon Aurora PostgreSQL.
3. Users access the chatbot from various devices, and their queries are handled by Amazon API Gateway, which routes requests to the backend.
4. API Gateway forwards requests to Amazon EKS, hosting both the Angular UI and Node.js backend, with the ability to handle multiple requests and scale vertically.
5. User requests are processed by an Amazon Lambda function that interacts with AWS services.
6. Lambda uses SageMaker to predict the query’s topic, adding it as additional context.
7. Lambda generates embeddings via Titan Express, filters the knowledge base by topic, and retrieves relevant document content from Amazon Aurora and S3.
8. The relevant content is attached to a prompt retrieved from AWS Systems Manager Parameter Store.
9. The prompt is sent to Amazon Bedrock, which generates responses using a pre-trained LLM.
10. Bedrock Guardrails ensure the responses meet safety, ethical, and business standards, filtering or validating as needed.
11. Once validated, the response is sent back through the Node.js backend and returned to the user via API Gateway.
Conclusion
In conclusion, augmenting LLMs with traditional machine learning techniques offers a practical solution to one of the most persistent challenges in AI—hallucinations. By integrating the generative power of LLMs with the precision and reliability of traditional ML models, we can create more accurate, trustworthy, and data-grounded outputs.
The real-world examples showcased in this blog demonstrate the effectiveness of this hybrid approach in improving the robustness of AI-driven systems. As businesses and developers continue to explore and refine these techniques, the synergy between LLMs and traditional ML will undoubtedly play a pivotal role in shaping the future of AI applications, delivering better insights and driving more informed decision-making processes.
Ready to discover how combining Large Language Models with traditional machine learning reduces AI hallucinations and enhances accuracy? Explore real-world examples of this hybrid approach.


